🔝 Top 30 Data Engineering Interview Questions & Answers


Hello dears, I’ve just recently landed a new job as a Senior Data Engineer at TripAdvisor and I went through tons of Data Engineering interviews.
While this is fresh in my mind, let me share with you the most common Data Engineering questions I’ve had, plus questions from my fellow Senior Data Engineers, what do they ask at the interviews.
Btw, you can also find Data Job Board there - https://www.nataindata.com/blog/entry-level-data-jobs/
Data Engineering interview structure
In general, it consists of an intro, where you tell about yourself, outlining past projects, and technologies you’ve used; then listen about what the company is doing - their stack, etc.
The next part typically consists of DE theoretical questions which I am gonna share in the next chapter;
After that, you can jump on some live coding steps - like SQL, or Python.
Watch full episode
💬 DATA ENGINEERING INTERVIEW QUESTIONS
Okay, let’s go to the real theoretical questions you might stumble on.
I’ve divided those into categories and marked BASIC or INTERMEDIATE tag 🏷️.
✏️ Data Modeling
- Data Lake vs Data Mart - 🏷️ Basic
Data lake is a more extensive and flexible data repository that can store vast amounts of raw, unstructured, or structured data at a relatively low cost.
Data mart is a tailored, structured subset of the data lake designed for specific analytical needs.
- What is a dimension? - 🏷️ Basic
Dimensions provide the “who, what, where, when, why, and how” context surrounding a business process event. Like, qualitative data.
- What are Slowly Changing Dimensions? - 🏷️ Basic
Relatively static data which can change slowly but unpredictably. Examples are names of geographical locations, customers, or products.
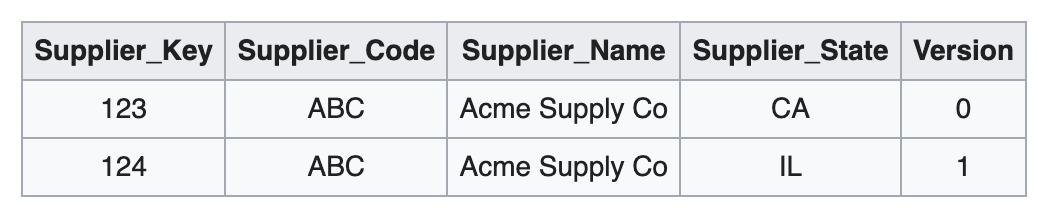
- What are slowly Changing Dimension Techniques? Name a few - 🏷️ Intermediate
- Type 0: Retain original
- Type 1: Overwrite
- Type 2: Add new row
- Type 3: Add new attribute
- Type 4: Add mini-dimension
- Type 5: Add mini-dimension and Type 1 outrigger
- Type 6: Add Type 1 attributes to Type 2 dimension
- Type 7: Dual Type 1 and Type 2 dimensions

- How to define a fact table granularity - 🏷️ Basic
By granularity, we mean the lowest level of information that will be stored in the fact table.
1) Determine which dimensions will be included
2) Determine where along the hierarchy of each dimension the information will be kept.
- Star-Schema vs 3NF vs Data Vault vs One Big Table - 🏷️ Basic
Star Schema:
- Design Focus: Designed for data warehousing and analytical processing.
- Structure: Central fact table surrounded by dimension tables.
- Performance: Optimized for query performance with fewer joins.
- Simplicity: Simple to understand and query, suitable for reporting and analysis.
- Use Case: Optimal for analytical processing and reporting in data warehousing scenarios.
3NF (Third Normal Form):
- Design Focus: Emphasizes data normalization to eliminate redundancy and maintain data integrity.
- Structure: Tables are normalized, and non-prime attributes are non-transitively dependent on the primary key.
- Performance: May involve more complex joins, potentially impacting query performance.
- Use Case: Suitable for transactional databases where data integrity is critical.
Data Vault:
- Design Focus: Agility in data integration.
- Structure: Hub, link, and satellite tables to capture historical data changes.
- Scalability: Scalable and flexible for handling changing business requirements and schema change
- Agility: Enables quick adaptation to changes.
- Use Case: Ideal for large-scale enterprises with evolving data integration needs.
One Big Table:
- Design Focus: A denormalized approach, consolidating all data into a single table.
- Structure: Minimal use of joins, as all data is in one table.
- Performance: Can provide quick query performance, reduce the amount of shuffling
- Simplicity: Simple structure but can lead to data redundancy & issues with data quality
- Use Case: If data volume grows and common JOINs are >10 Gb, data analysts know more beyond basic sql
- Normalization vs Denormalization - 🏷️ Intermediate
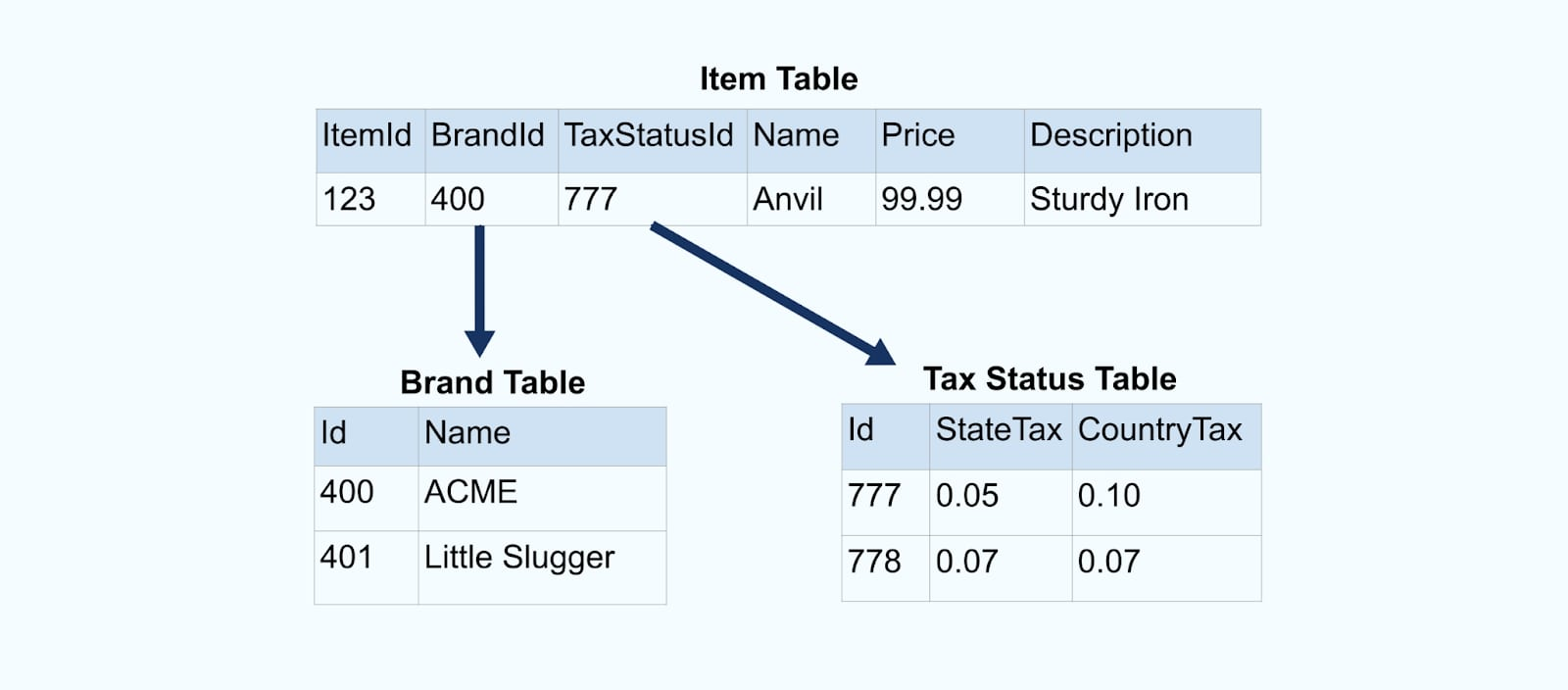
Normalization:
- Objective: To reduce data redundancy and improve data integrity by organizing data into well-structured tables.
- Process: It involves decomposing large tables into smaller, related tables to eliminate data duplication.
- Normalization Forms: Follows normalization forms (e.g., 1NF, 2NF, 3NF) to ensure the elimination of different types of dependencies and anomalies.
- Use Cases: Commonly used in transactional databases where data integrity and consistency are critical.
Denormalization:
- Objective: Inverse process of normalization, to improve query performance by reducing the number of joins needed to retrieve data.
- Process: Combining tables and introducing redundancy, allowing for faster query execution.
- Data Duplication: Denormalized tables may contain duplicated data to minimize joins
- Complexity: Denormalized databases are often simpler to query but may be more challenging to maintain as they can be prone to data anomalies.
- Use Cases: Typically employed in data warehousing
✏️ Database
- Structured vs semi-structured vs unstructured data - 🏷️ Basic
- Structured data: Structured data refers to data that is organized in a specific, pre-defined format and is typically stored in databases or other tabular formats. It is highly organized and follows a schema
- Semi-structured data: It is information that does not reside in a relational database but that has some organizational properties that make it easier to analyze. Example: XML data.
- Unstructured data: It is based on character and binary data. Example: Audio, Video files, PDF, Text, etc.
- Define OLTP and OLAP. What is the difference? What are their purposes? - 🏷️ Basic
| 🍏 OLTP | 🍎 OLAP | |
| BASIS | Online Transactional Processing system to handle large numbers of small online transactions | Online Analytical Processing system for data retrieving and analysis |
| FOCUS | INSERT, UPDATE, DELETE operations | Complex queries with aggregations |
| OPTIMISATION | Write | Read |
| TRANSACTIONS | Short | Long |
| DATA QUALITY | ACID compliant | Data may not be as organized |
| EXAMPLE | E-commerce purchases table | Average daily sales for the last month |
- ETL vs ELT - 🏷️ Basic
ETL 📤 🧬 ⬇️ - 📤 Extraction of data from source systems, doing some 🧬 Transformations (cleaning) and finally ⬇️ Loading the data into a data warehouse.
ELT 📤 ⬇️ 🧬 - With allowance of separation of storage and execution, it has become economical to store data and then transform them as required. All data is immediately Loaded into the target system (either a data warehouse, data mart or data lake). This can include raw, unstructured, semi-structured and structured data types. Only then data is transformed in the target system to be analyzed by BI tools or data analytics tools
- ACID vs BASE - 🏷️ Intermediate
- ACID (Atomicity, Consistency, Isolation, Durability) principle - is typically associated with traditional relational database management systems (RDBMS), where data consistency and integrity are of utmost importance.
- BASE (Basically Available, Soft state, Eventually consistent) - is often linked to NoSQL databases and distributed systems, where high availability and partition tolerance are prioritized, and strong consistency may be relaxed in favor of availability and partition tolerance.
- What is CDC? - 🏷️ Intermediate
Change Data Capture. It is a set of processes and techniques used in databases to identify and capture changes made to the data. The primary purpose of CDC is to track changes in source data so that downstream systems can be kept in sync with the latest updates.
Types of Changes:
- Inserts: Identifying newly added records.
- Updates: Capturing changes made to existing records.
- Deletes: Recognizing when records are removed.
Methods:
- Timestamps on rows
- Version numbers on rows
- Status indicators on rows, etc.
✏️ Python
- Name immutable and mutable data types in Python - 🏷️ Basic
Immutable objects are usually hashable, meaning they have a fixed hash value.
- Immutable Data Types: Tuples, Strings, Integers, Floats, Booleans, Frozen Sets
- Mutable Data Types: Lists, Dictionaries, Sets, Byte Arrays
- Python Data Structures - 🏷️ Basic
Python provides several built-in data structures: Lists, Tuples, Sets, Dictionaries, Strings, Arrays, Queues, Stacks
✏️ SQL
- What is SQL execution order? - 🏷️ Basic
SQL Order of Operations:
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- HAVING
- WINDOW FUNCTIONS
- SELECT
- DISTINCT
- ORDER BY
- LIMIT
- What is a Primary Key - 🏷️ Basic
The PRIMARY KEY constraint uniquely identifies each row in a table. It must contain UNIQUE values and has an implicit NOT NULL constraint
- TRUNCATE, DELETE and DROP statements - 🏷️ Intermediate
- DELETE statement is used to delete rows from a table.
- TRUNCATE command is used to delete all the rows from the table and free the space containing the table.
- DROP command is used to remove an object from the database. If you drop a table, all the rows in the table are deleted and the table structure is removed from the database.
- What is common table expression (CTEs)? - Basic 🏷️
CTE is a named temporary result set which is used to manipulate the complex sub-queries data. This exists for the scope of a statement. You cannot create an index on CTE.
- List the different types of relationships in SQL - 🏷️ Intermediate
- One-to-One - This can be defined as the relationship between two tables where each record in one table is associated with the maximum of one record in the other table.
- One-to-Many & Many-to-One - This is the most commonly used relationship where a record in a table is associated with multiple records in the other table.
- Many-to-Many - This is used in cases when multiple instances on both sides are needed for defining a relationship.
- Self-Referencing Relationships - This is used when a table needs to define a relationship with itself.
- What is an Index - 🏷️ Intermediate
A database index is a data structure that provides a quick lookup of data in a column or columns of a table. It enhances the speed of operations accessing data from a database table at the cost of additional writes and memory to maintain the index data structure.
Indexes are typically created on one or more columns of a database table and contain a copy of the data in the indexed columns along with a pointer to the corresponding row in the table. When a query is executed that includes a search condition on the indexed column(s), the DBMS can use the index to quickly identify the rows that satisfy the condition, significantly reducing the time and resources required for the operation.
- Explain the complexity of index operations - 🏷️ Intermediate
- Insertion & Deletion - When a new record is inserted/deleted into a table with indexes, the DBMS needs to update the index to include the new data. The complexity of this operation depends on the type of index and the database system but is typically O(log n) or O(1) for most practical purposes. However, in some cases, if the index structure needs to be rebalanced or modified, it can approach O(n), where n is the number of rows in the table.
- Search (Lookup): Searching for a specific record based on an indexed column is typically very efficient, with a complexity of O(log n) in the case of B-tree and balanced tree indexes, and O(1) for hash indexes. This means that the time it takes to find a specific record does not increase linearly with the size of the table.
✏️ Airflow
- What are the components used by Airflow? - 🏷️ Basic
- Web Server - used for tracking the status of our jobs and in reading logs from a remote File Store
- Scheduler - used for scheduling our jobs and is a multithreaded python process which use DAGb object
- Executor - used for getting the tasks done
- Metadata Database - used for storing the Airflow States
- What are the types of Executors in Airflow? - 🏷️ Basic
- Local Executor - Helps in running multiple tasks at one time.
- Sequential Executor - Helps by running only one task at a time.
- Celery Executor - Helps by running distributed asynchronous Python Tasks.
- Kubernetes Executor - Helps in running tasks in an individual Kubernetes pod.
- What are XComs In Airflow - 🏷️ Intermediate
XComs (short for cross-communication) are messages that allow data to be sent between tasks. The key, value, timestamp, and task/DAG id are all defined
✏️ Infrastructure
- What is CI/CD? - 🏷️ Basic
CI/CD, or Continuous Integration and Continuous Delivery/Deployment, is a set of software development practices that automate the integration, testing, and delivery of code changes. It involves regularly merging code changes from multiple contributors (GIT), automatically building and testing the software, and delivering it to various environments.
- Terraform: Explain main CLI commands - 🏷️ Basic
- init - Prepare your working directory for other commands
- validate - Check whether the configuration is valid
- plan - Show changes required by the current configuration
- apply - Create or update infrastructure
- destroy - Destroy previously-created infrastructure
✏️ Spark
- What is Apache Spark, and how does it differ from Hadoop MapReduce? In a nutshell - 🏷️ Basic
Apache Spark is an open-source, distributed computing system providing fast, in-memory data processing for big data analytics. Spark is faster, more versatile, and developer-friendly compared to MapReduce, offering in-memory processing and a broader range of libraries for big data analytics.
- Spark performs in-memory processing, reducing disk I/O and speeding up tasks. MapReduce reads and writes to disk, making it slower for iterative algorithms.
- Spark offers high-level APIs in multiple languages, making development more accessible. MapReduce involves more complex and verbose code.
- Spark is well-suited for iterative algorithms due to in-memory caching. MapReduce is less efficient for iterative tasks
- Explain the core components of Apache Spark - 🏷️ Intermediate
- Driver Program - Initiates Spark application, and defines execution plan.
- SparkContext - Coordinates tasks, manages resources, communicates with Cluster Manager.
- Cluster Manager - Allocates resources, manages nodes in the Spark cluster.
- Executor - Worker processes on cluster nodes, execute tasks, store data.
- Task - Unit of work sent to Executor for execution.
- RDD (Resilient Distributed Dataset) - Immutable, distributed collection of objects processed in parallel.
- Spark Core - Foundation providing task scheduling, memory management, fault recovery.
Also have Spark SQL, Spark Streaming, MLlib, GraphX, SparkR libs
✏️ Cloud
- What is a distributed computing? - 🏷️ Basic
Distributed computing refers to the use of multiple computer systems, (nodes or processors), to work collaboratively on a task or solve a problem. Instead of relying on a single, powerful machine, distributed computing leverages the combined processing power and resources of multiple interconnected devices.
There are several reasons to use distributed computing:
- Parallel Processing: Distributed computing allows a task to be divided into smaller sub-tasks that can be processed simultaneously by different nodes.
- Fault Tolerance: If one node in a distributed system fails, the others can continue working.
- Scalability: Distributed systems can easily scaled (scale up or scale out). This makes it possible to handle larger workloads or more extensive datasets.
- Resource Utilization: By distributing tasks across multiple machines, the overall resources of a network can be used more efficiently. This is particularly important for large-scale computational tasks.~~
Distributed Compute was evolving from SMP (Symmetric Multiprocessing) to MPP (Massively Parallel Processing) and lastly EPP (Elastic Parallel Processing)


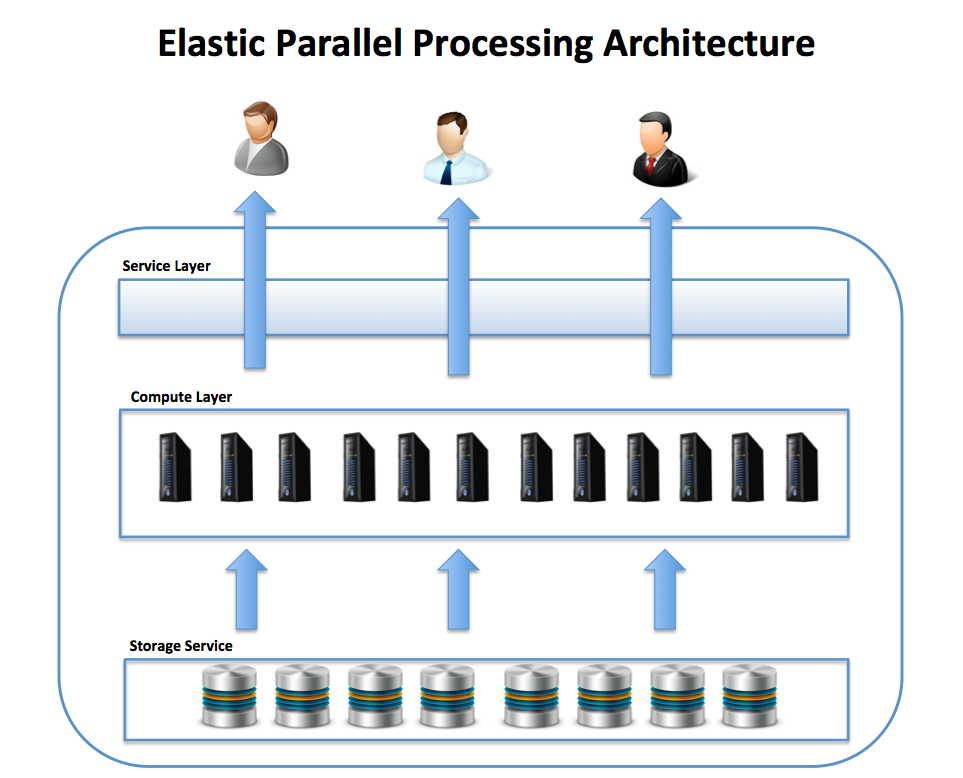
- Describe some best practices to reduce / control costs when making queries in Cloud Data Warehouse - 🏷️ Intermediate
Here many options are available, but let’s outline a couple of them:
- Don't use SELECT *
- Aggregate Data - When appropriate, use aggregates to pre-calculate results and reduce the amount of computation needed.
- Filter by PARTITION column
- Filter by CLUSTERED column
- Use PREVIEW instead SELECT when you want to analyze table contents
- Implement data retention policies to automatically archive or delete data that is no longer needed.
- In some cases, denormalize tables to reduce the need for complex joins and improve query performance.
- Use materialized views to store precomputed results and reduce the need for expensive computations during queries.
- Select the appropriate instance types based on your workload requirements to avoid over-provisioning.
- etc.
So these are 30 Data Engineering Interview Questions. If you want to hear more questions on DATA STRUCTURES & ALGORITHMS - post your comments below and I might take it into my backlog 🙂
Until then, stay curious!